Zookeeper
Zookeeper
概述
zookeeper是Yahoo开发的后来贡献给了Apache,是用于分布式管理和协调的框架。
提供了中心化的服务:统一的配置、统一的命名、提供分布式锁,以及提供组服务
安装
单机模式
就是解压就可用,只能使用一部分功能,往往是学习阶段刚入手使用
伪分布式模式
是在一台机器上,利用多线程模拟不同的角色,来达到集群的效果,能够启动大部分功能,可以满足学习阶段使用
完全分布式模式
在多台机器上安装,每一台机器都扮演自己的角色,一般情况下生产模式中使用
单机
解压即可,注意路径中没有中文和空格
找到conf/zoo_sample.cfg文件,复制一份更名为zoo.cfg,
zoo.cfg中有一个dataDir属性,是ZK运行期间数据的存放目录
直接双击zkServer.cmd脚本运行ZK的服务端即可
找到zkCli.cmd脚本运行ZK的客户端
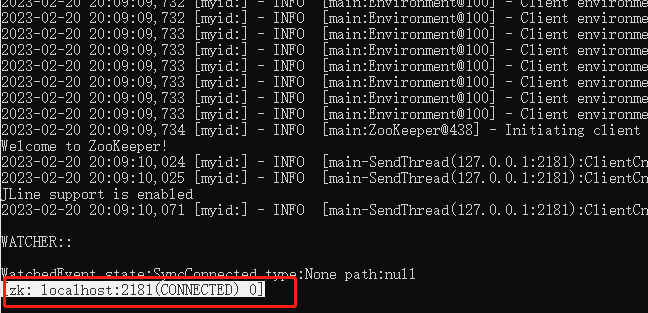
有以上提示,就是客户端连接成功,如果只显示了None paht:null,回车即可有以上提示
ZK特点
- ZK的底层是一个树状结构,根节点是 /
- ZK自带了一个子节点 /zookeeper
- ZK中没有相对路径的概念,只有绝对路径
- ZK中每一个节点称之为Znode节点,所以这棵树也称为Znode树
- ZK在创建节点的时候,可以携带数据也可以不携带数据(3.5.7之前的版本必须携带数据,之后的版本可以不携带),数据可以是对节点的描述,或者可以是一些配置信息
- zookeeper中携带的数据存储在内存以及磁盘中
- ZK中数据的存储位置由dataDir属性决定的,默认是在/tmp目录下
- 在ZK中会将每一个写操作(创建、修改、删除)看成一个事务,并且会给这个事务分配一个全局递增的事务id,这个变化就是Zxid
- 临时节点不能挂载子节点,持久节点可以挂载子节点
- 在ZK中不能存在同名节点
ZK命令
| 命令 | 解释 |
|---|---|
| ls / [ls 节点名称] | 查看根节点的子节点 |
| create /video “123” | 创建节点video,并携带数据123 |
| get /video | 获取节点数据和节点详情 |
| stat /video | 获取节点详情 |
| set /video “123456” | 修改节点数据 |
| create -e /aa “aa” | 临时节点 |
| close | 关闭本次会话,但是不退出客户端 |
| connect ip:port | 连接到指定的服务器 |
| create -s /video | 创建持久顺序节点 |
| create -s -e /txt | 创建临时顺序节点 |
| delete /video | 删除没有子节点的节点 |
| rmr /video | 强制删除节点 |
ZK节点详情
1 | 123 节点数据 |
ZK节点类型
临时节点:主要退出本次会话就会失效
ZK的API
1 | <!--添加ZK的依赖--> |
1 | package cn.tedu.csmall.cart.webapi; |
搭建ZK集群
windows系统下的伪分布式
找到单机安装好的ZK,复制两份分别命名为zkServer1、zkServer2、zkServer3
ZK节点有三种角色:leader(1)、follower(n)、observer(n)
配置zoo.cfg
打开zkServer1中的conf下的zoo.cfg文件,添加以下内容
1 | dataDir=D:/zookeeper/data1 |
打开zkServer2中的conf下的zoo.cfg文件,添加以下内容
1 | dataDir=D:/zookeeper/data2 |
打开zkServer3中的conf下的zoo.cfg文件,添加以下内容
1 | dataDir=D:/zookeeper/data3 |
配置myid
带dataDir属性指定的目录下,创建myid文件(注意没有后缀)
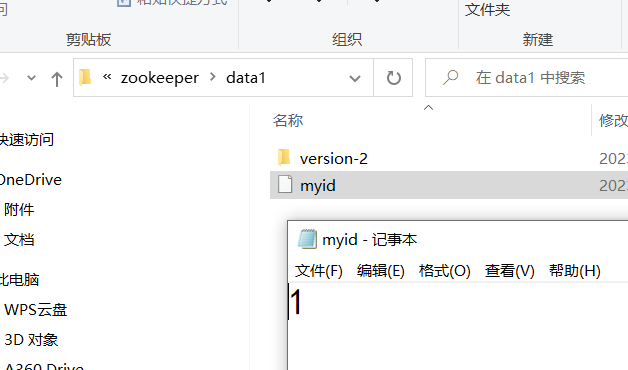
myid在zkServer1的内容: 1
myid在zkServer2的内容: 2
myid在zkServer3的内容: 3
myid中的值在集群中不允许重复
启动集群
分别启动三台ZK的bin目录下的zkServer.cmd,启动期间可能会报错,忽略即可,等三台启动结束就不会在报错了
利用netcat查看三台节点的状态
**下载课前资料的netcat **,解压即可(需要注意 ,会被当成病毒,所有关闭所有的查杀软件),有一个nc.exe脚本文件,复制nc.exe到C:\Windows\System32目录下,就可以全局可用(或者配置环境变量)
通过 echo stat|nc 127.0.0.1 2181来查看该节点的状态
1 | echo stat|nc 127.0.0.1 2181 |
如果发送命令一直未响应,需要重启ZK集群
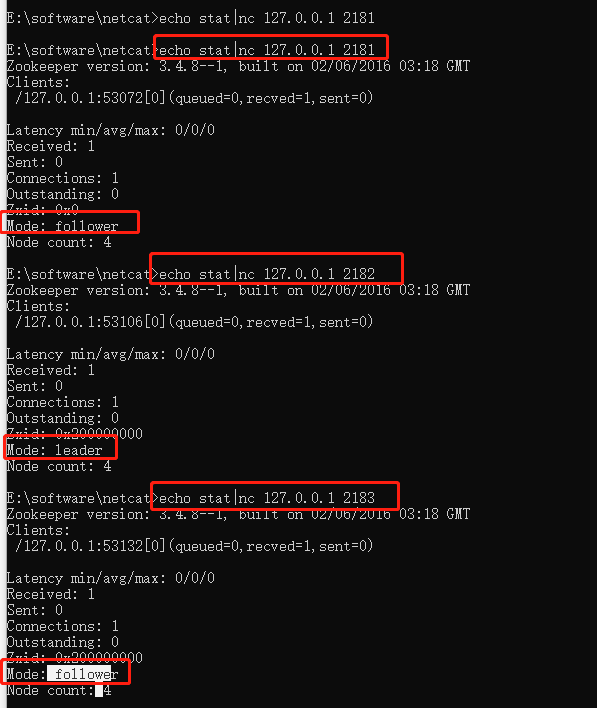
响应的内容,可能是上图所示
如果以上查看节点状态的命令无法使用,可以运行ZK客户端,输入
1 | connect 127.0.0.1:2181 |
如果能连接上,说明集群都没有问题
kafka配置外置的zookeeper集群
打开kafka的config目录下的server.properties
1 | zookeeper.connect=localhost:2181,localhost:2182,localhost:2183 |
ZK集群选举
有过半性,集群中半数以上的节点同意才能当leader
初次选举,看myid的值,谁大谁赢
非初次选举,看事务id,谁大谁赢
zk集群的容灾,也符合过半原则,ZK集群半数以上的节点存活集群才可用,所以一般情况下ZK集群是奇数台
过半存活的优点
防止脑裂,所谓脑裂就是指集群中出现两个及其以上的leader。
如果多台服务器放置在不同的机柜中,如果某一机柜突然断网,连不上,成为一个单独的个体,那么单独分出去的也会重新选举一个新的leader,又恢复网络,这个时候集群中出现了两个leader,这个就是脑裂现象
出现脑裂条件:集群产生分裂;分裂后产生选举
但是ZK集群中加入了过半性,如果分裂出去的不足一半是无法成功选举新的leader的
观察者
-
observer在zookeeper中即不参与选举也不参与投票,但是会监听选举和投票的结果,根据结果进行指定操作
-
observer可以理解成没有选举权和投票权的follower–只有干活的义务没有选举的权利
-
在实际开发中,当集群规模庞大(节点个数比较多)或者网络环境一般的时候,会将一个集群中90%~97%的节点设置为observer
a. 在集群规模庞大的时候,此时选举投票效率低
b. 在集群规模庞大的前提下,选举结果实际上会受网络环境的影响,如果网络环境的变化比较大,就可能会导致选举或者投票无效,从而触发新一轮的选举\投票,导致效率较低
c. 大部分节点设置成observer,可以提高效率
-
由于observer不参与投票也不参与选举,所以observer存活与否并不会影响整个集群是否对外提供服务。比如:21节点集群(1leader,6follower,14observer),如果四个follower宕机了,即便14个observer全部存活也不会对外提供服务了。但是如果leader和follower全部存活,14个observer全部宕机也不会影响集群对外提供服务。在ZK集群中,过半性是以能够参加选举或者投票的节点的个数来决定的。
-
observer的配置
a. 找打conf目录的下zoo.cfg
b. 添加server.1=B:C:D:observer





